Claude
Sonnet 5
Codenamed "Fennec". Reportedly one full generation ahead of Gemini's "Snow Bunny". Optimized for agentic workflows, advanced coding capabilities, and next-generation reasoning efficiency.
claude-sonnet-5@20260203
Agentic "Dev Team" Mode
Leaks indicate a new capability to spawn specialized sub-agents (backend, QA, researcher) that work in parallel from the terminal. Agents run autonomously in the background - you give a brief, they build the full feature like human teammates.
- Autonomous feature building from briefs
- Specialized sub-agents working in parallel
- Terminal-based collaboration interface
TPU Acceleration
Allegedly trained and optimized on Google TPUs, enabling higher throughput and lower latency. Retains the 1M token context window but runs significantly faster than previous generations.
Benchmark Comparison
Based on leaked internal evaluation data
| Metric | Sonnet 5 (Rumored) | Opus 4.5 | GPT-5 Codex |
|---|---|---|---|
| SWE-Bench Verified | > 80.9% | 77.2% | 74.9% |
| OSWorld (Computer Use) | > 85% | 61.4% | -- |
| Context Window | 1M Tokens | 1M (API) | 128k - 1M |
| Inference Speed | High (TPU Native) | Moderate | High |
* All benchmarks are based on unverified leaks and subject to change upon official release.
Leak Timeline
Imminent Release
Current speculation points to a February 3rd launch window, aimed at capturing the Q1 narrative before competitor releases.
Vertex AI Confirmation
Model identifier claude-sonnet-5@20260203 spotted in Google Vertex AI error logs. A 404 error on the specific Sonnet 5 ID suggests the model already exists in Google's infrastructure, awaiting activation.
Initial Rumors
Early reports from forecasting platforms and industry insiders suggested a Q1-Q2 2026 window. Some early claims of a 10M context window have since been tempered to a more realistic 1M high-speed context.
Claude Opus 4.6
Anthropic's latest flagship model. 1M token context (beta), Agent Teams, self-correction on long tasks, and 2.5x faster inference already in testing. The community verdict: a generational leap.
Official & Community Benchmarks
Compiled from Anthropic's announcement and third-party reproductions
| Benchmark | Opus 4.6 | GPT-5.2 | Notes |
|---|---|---|---|
| SWE-Bench Verified | 80.9% | -- | Industry leading |
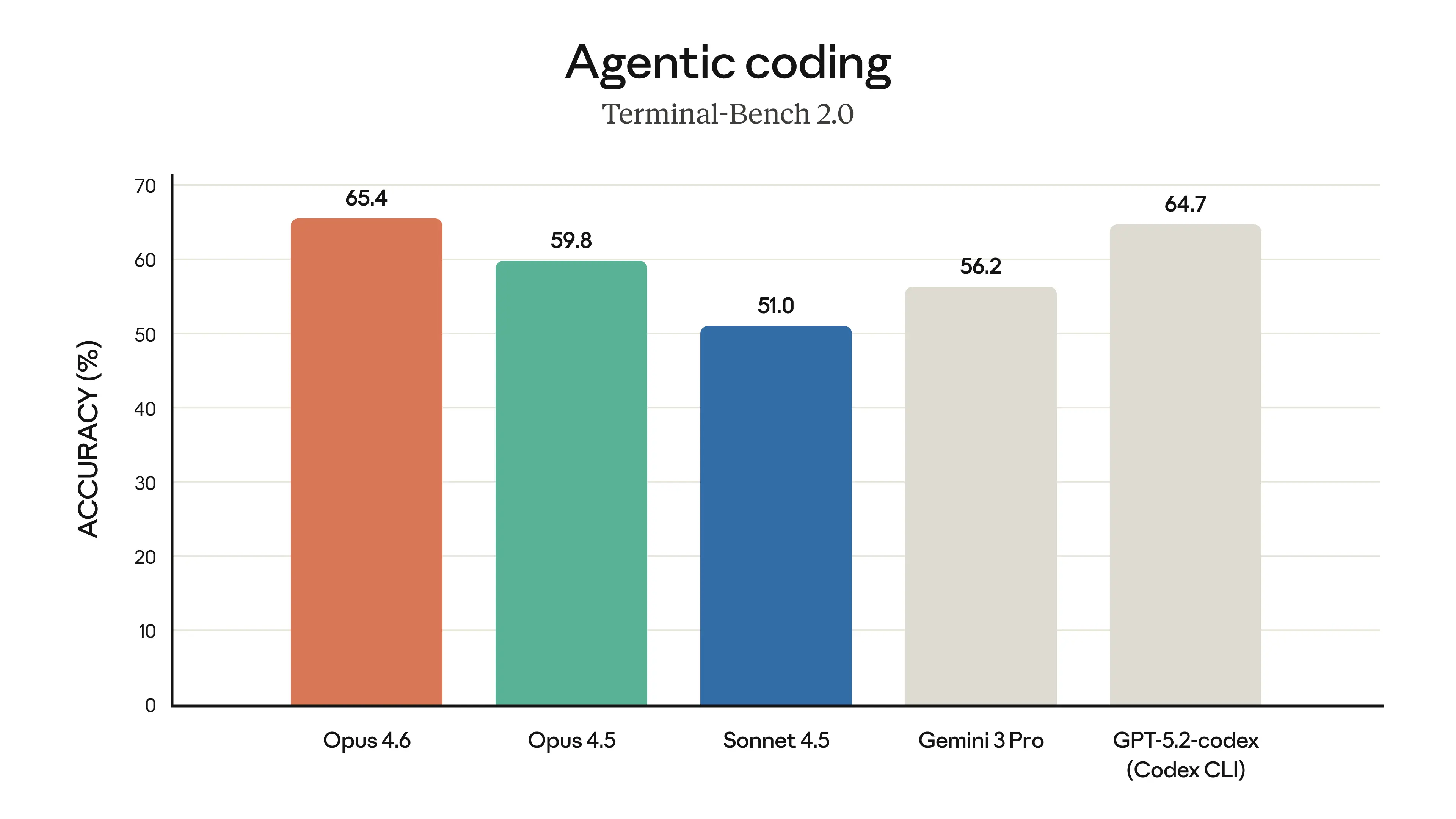
| Terminal-Bench 2.0 | 65.4% | -- | Highest agentic coding score |
| BigLaw Bench | 90.2% | -- | Legal reasoning |
| OSWorld | 66.3% | -- | Computer use |
| GDPval-AA | +144 Elo | baseline | Knowledge work value |
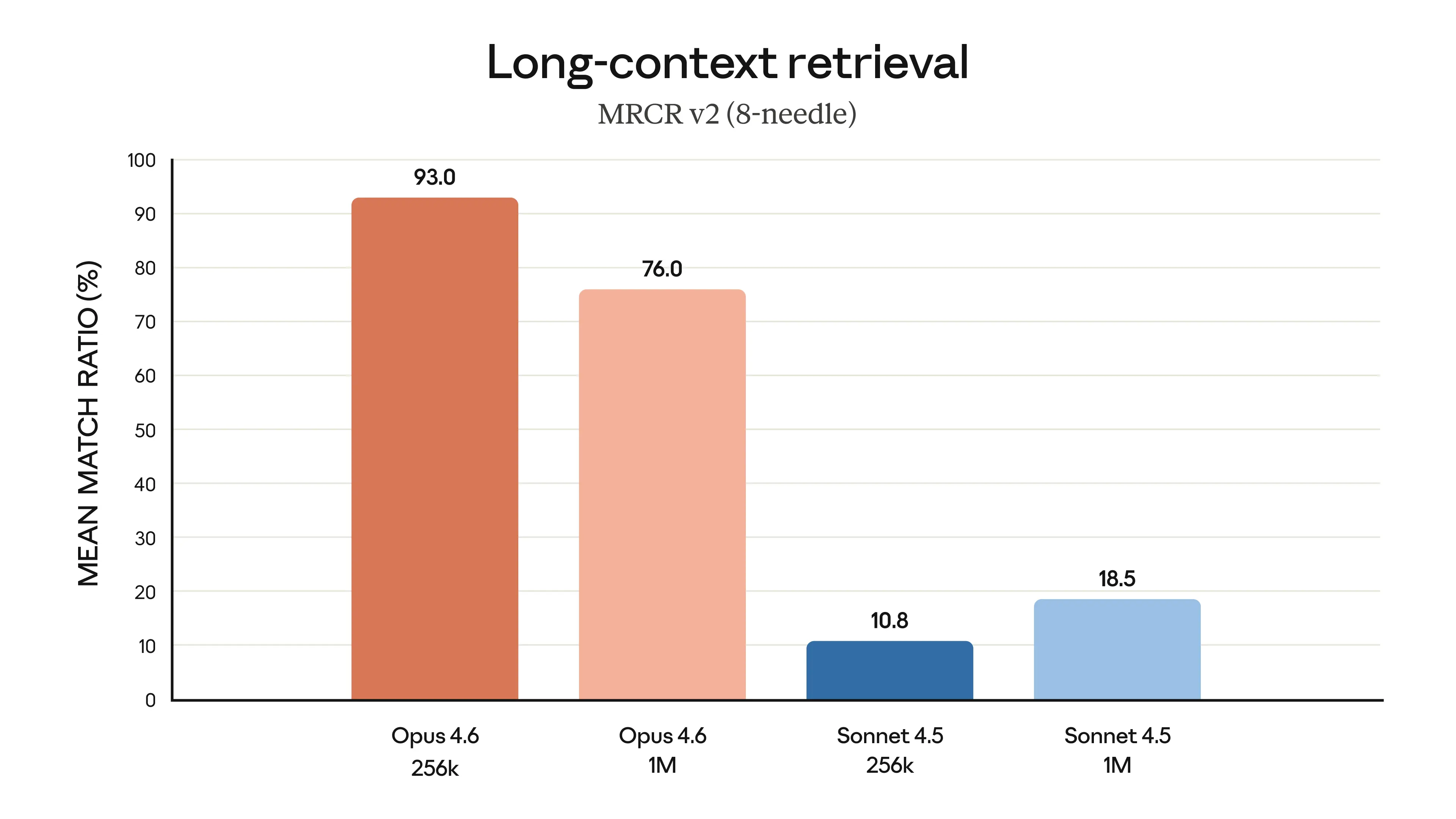
| Long Context Retrieval (1M) | 76% | -- | Sonnet 4.5 was 18.5% |
Source: @sairahulxGTM benchmark compilation — the most-shared independent benchmark post on X.
Benchmark Visuals



Community Highlights
427x Kernel Optimization Speedup
@scaling01Experimental scaffold achieved 427x acceleration, far exceeding the 300x human-expert threshold. Standard scaffold still hit 190x. A landmark result for AI-driven systems optimization.
Full Agentic Game Dev in 24 Hours
@NicolasZu · 1k+ likesBuilt entirely with Opus 4.6 + GPT-5.3-Codex Agent Teams. Added minimap, shooting mechanics, zombies-per-minute system, UI, and voice alerts in 24 hours. Zero hand-written code, still running at 60fps+.
Google Antigravity Integrates Opus 4.6
@tsumulog_aiAvailable to free-tier users (occasional 503 errors). Community feedback: "Code that Gemini couldn't fix, Opus 4.6 nails in one shot."
Community Benchmark Compilation
@sairahulxGTMThe most-shared independent benchmark post. SWE-Bench 80.9%, Terminal-Bench 65.4%, BigLaw 90.2%, OSWorld 66.3% — across-the-board dominance over GPT-5.2.